

Table of contents
- Introduction
- 1. Log into Lightning.ai and set up environment
- 2. Install dependencies
- 3. Log into Weights & Biases
- 4. Download the Base Model
- 5. Create and Modify Torchtune Configuration File
- 6. Run Fine-tuning sanity check against CPU
- 7. Switch to a GPU-backed Environment
- 8. Run Your Fine-tuning Job
- 9. Publish Your Fine-tuned Model
- 10. Verify your Fine-tuned Model
Introduction
In this tutorial, I'll walk you through fine-tuning the Llama 3.1-8B-Instruct model using Torchtune on the Lightning.ai platform.
In a recent review I wrote of cloud GPU services for Jupyter Notebooks, Lightning.ai stood out as one of the best experiences available for running a Jupyter Notebook in a native IDE and easily switching to GPU environments when ready to run real workloads.
If you'd like to learn more about fine-tuning and how LoRA (Low-Rank Adaptation) works, check out: What is LoRA and QLoRA?
1. Log into Lightning.ai and set up environment
- Log into Lightning.ai. If you haven't used Lightning.ai yet, you'll need to create an account, and you may need to wait one day or so for your account to be approved.
- Import the companion Jupyter Notebook for this project by clicking the New file button in the top-left corner and selecting "Upload Notebook".
- Initially, select a free CPU-backed studio to set up and test our environment.
This allows us to set up our environment and ensure everything is working correctly before we move to GPU resources for the actual fine-tuning process.
2. Install dependencies
Now that we have our Notebook set up in Lightning.ai Studio, let's install the necessary libraries:
!pip install -U torchtune==0.2.1 torchao wandb peft sentencepiece transformers
3. Log into Weights & Biases
Next, we'll log in to Weights & Biases for experiment tracking.
wandb.login()
Note that when you run this cell, you'll get output that links you to your Weights & Biases token page.
Go to that URL copy out your token and paste it into the dialog box in the Notebook cell output, then press Enter to continue.
If all worked well, you should see output like this:
True
There's another piece you need to configure in step #5, under the metric_logger section,
to tell Torchtune to send logs and metrics to your Weights & Biases project. Be sure to replace write_like_me with the name of your project.
Once you've fully configured your Weights & Biases project, you'll be able to log into your W&B dashboard and see your metrics during Fine-tuning:
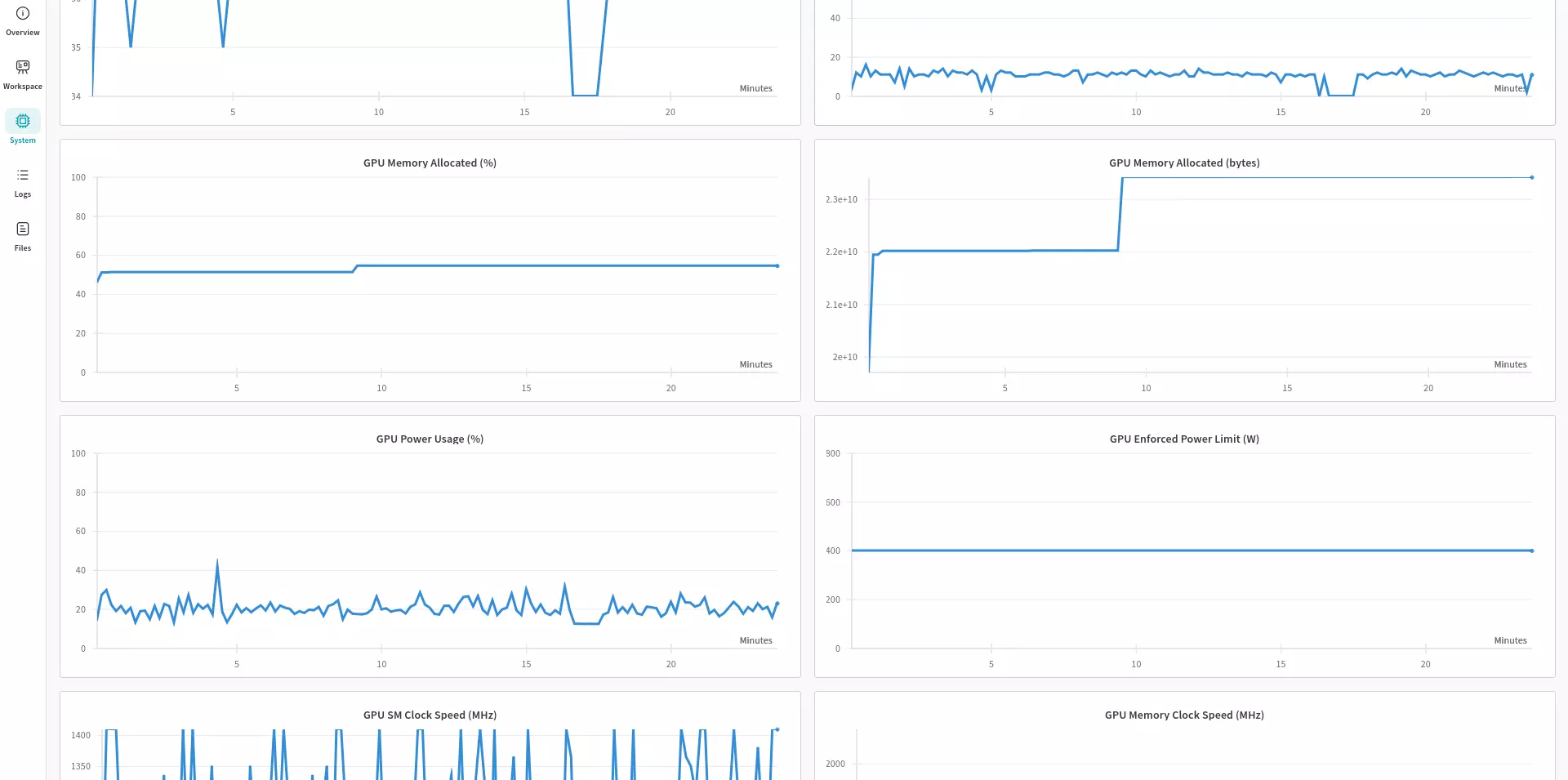
4. Download the Base Model
We'll use the tune download command to fetch the Meta-Llama-3.1-8B-Instruct model from the Hugging Face Model Hub:
!tune download meta-llama/Meta-Llama-3.1-8B-Instruct --ignore-patterns=null
This command downloads the model and its weights, storing them in /tmp/Meta-Llama-3.1-8B-Instruct by default.
5. Create and Modify Torchtune Configuration File
Torchtune, a native PyTorch library, provides pre-configured recipes for various steps in the model lifecycle.
You access available recipes with the tune ls (show recipes) and the tune cp (copy recipe) commands:
tune ls
RECIPE CONFIG
full_finetune_single_device llama2/7B_full_low_memory
mistral/7B_full_low_memory
full_finetune_distributed llama2/7B_full
llama2/13B_full
mistral/7B_full
lora_finetune_single_device llama2/7B_lora_single_device
llama2/7B_qlora_single_device
mistral/7B_lora_single_device
...
You can then run tune cp to copy the recipe to your local directory as YAML, at which point you can edit the parameters to customize the recipe to your needs.
❯ tune cp llama3_1/8B_qlora_single_device my_conf
Copied file to my_conf.yaml
The following configuration file shows some of the key modifications I made:
# Config for single device QLoRA with lora_finetune_single_device.py
# using a Llama3.1 8B Instruct model
model:
_component_: torchtune.models.llama3_1.qlora_llama3_1_8b
lora_attn_modules: ['q_proj', 'k_proj', 'v_proj']
apply_lora_to_mlp: False
apply_lora_to_output: False
lora_rank: 8
lora_alpha: 16
tokenizer:
_component_: torchtune.models.llama3.llama3_tokenizer
path: /tmp/Meta-Llama-3.1-8B-Instruct/original/tokenizer.model
# Dataset and Sampler
dataset:
_component_: torchtune.datasets.instruct_dataset
source: zackproser/writing_corpus
data_files: 'training_data.jsonl'
template: torchtune.data.AlpacaInstructTemplate
train_on_input: False
split: train
seed: 42 # Set a fixed seed for reproducibility
shuffle: True
batch_size: 1
max_seq_length: 2048 # Reduced to prevent OOM issues
# ... (rest of the configuration)
# Use Weights & Biases for logging
metric_logger:
_component_: torchtune.utils.metric_logging.WandBLogger
project: write_like_me
The dataset section is where you can modify the dataset you use to fine-tune your model. You could use your own Hugging Face dataset, by passing it in the source key, like so:
dataset:
_component_: torchtune.datasets.instruct_dataset
source: zackproser/writing_corpus
data_files: 'training_data.jsonl'
template: torchtune.data.AlpacaInstructTemplate
train_on_input: False
split: train
seed: 42
You could also use a local dataset, by passing in a filepath to a JSONL file, like so:
dataset:
_component_: torchtune.datasets.instruct_dataset
source: /path/to/your/local/dataset.jsonl
template: torchtune.data.AlpacaInstructTemplate
train_on_input: False
split: train
seed: 42
See my article on How to create a custom dataset for fine-tuning Llama 3.1 for more details on creating a custom dataset.
6. Run Fine-tuning sanity check against CPU
Before we start the actual fine-tuning process, let's run a small test to ensure everything is set up correctly and logging to Weights & Biases:
!tune run lora_finetune_single_device --config llama_wandb_qlora.yaml --max-steps 10
Running this smoke test against the CPU also ensures there are no configuration issues, such as missing files or wrong paths, (which don't appear until training is underway).
If everything looks good, we're ready to switch to a GPU-backed environment for the real fine-tuning run.
7. Switch to a GPU-backed Environment
Now that we've confirmed our setup is working, let's switch to a GPU-backed environment in Lightning.ai Studio for the actual fine-tuning process:
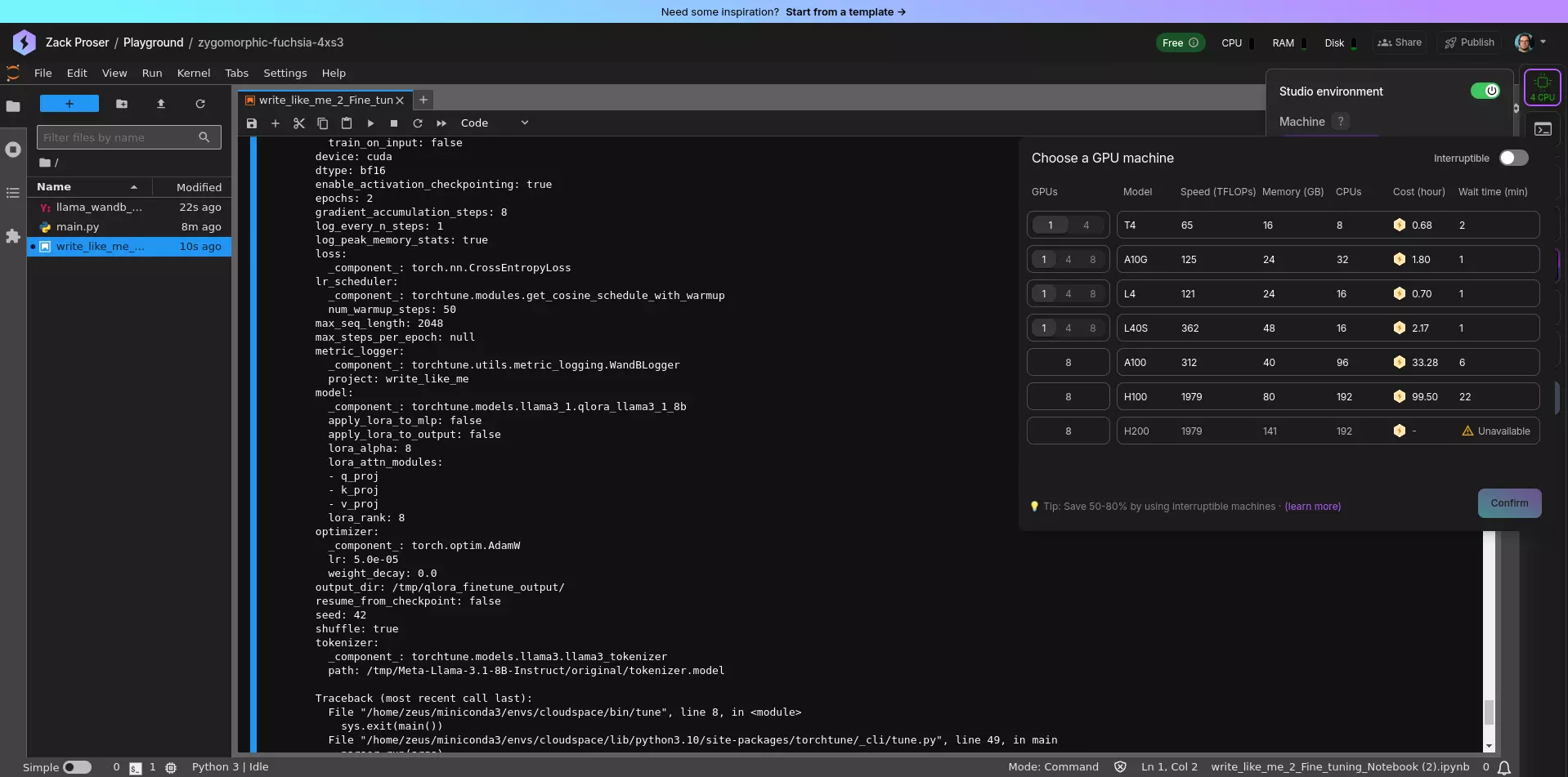
In the top-right corner of the Studio, click on the icon that says "4 CPU", which opens the GPU picker, allowing you to view the different GPU options available.
Once you've selected a GPU-backed environment, reopen your Notebook and proceed with the full fine-tuning run.
8. Run Your Fine-tuning Job
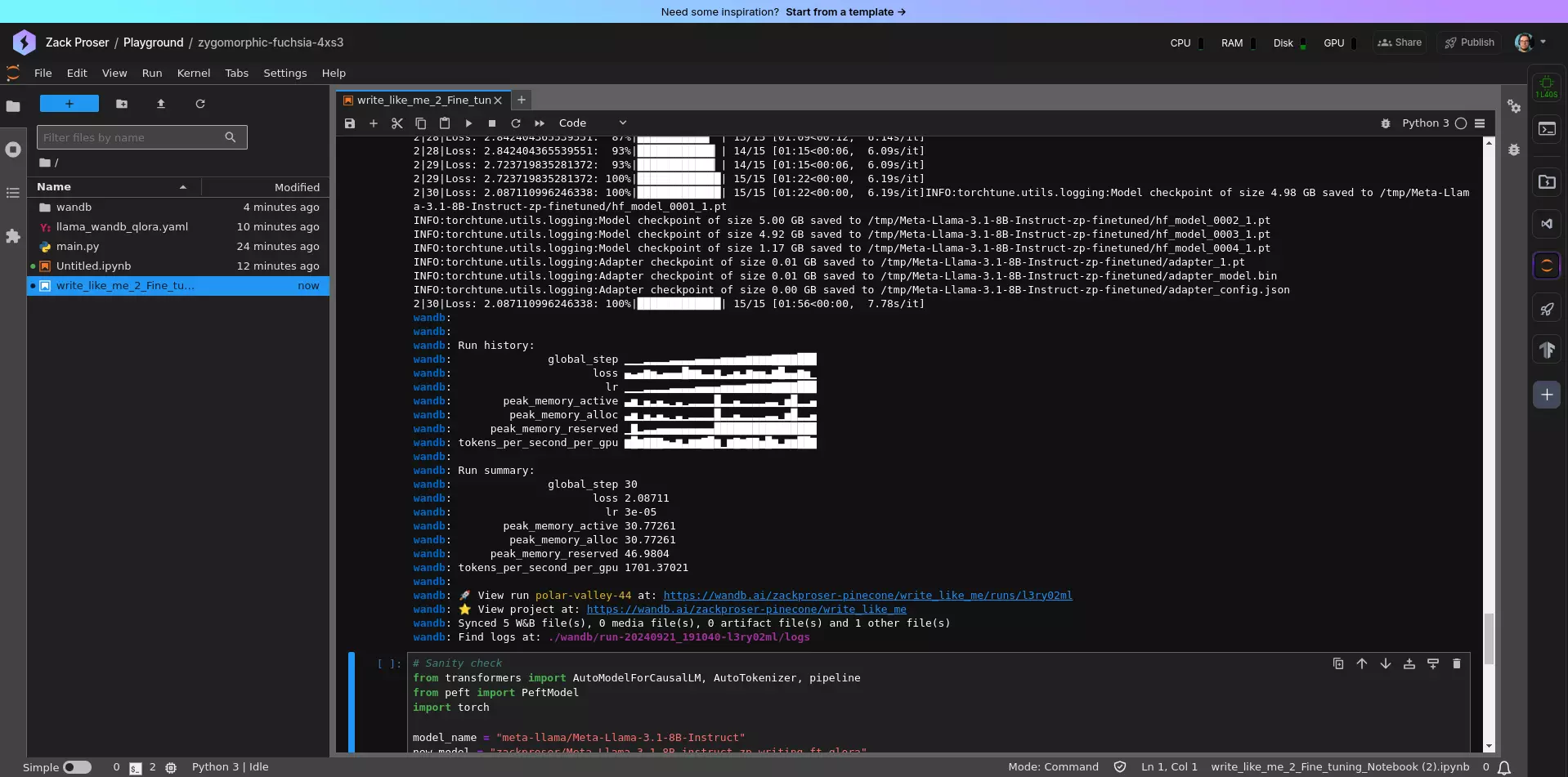
With our GPU-backed environment ready, we can start the full fine-tuning process:
!tune run lora_finetune_single_device --config llama_wandb_qlora.yaml
This command initiates the fine-tuning process using our defined configuration. The process will log metrics to Weights & Biases, allowing us to monitor the training in real-time.
9. Publish Your Fine-tuned Model
Upload your fine-tuned model to the Hugging Face Hub for easy access and sharing.
Prior to doing so, you'll need to export your Hugging Face token to your environment:
os.environ['HF_TOKEN'] = '<your-hf-token>'
In the following example command, replace <your-username> with your actual username on the Hugging Face platform,
and replace <your-model-name> with a name of your choosing for your fine-tuned model. If you don't already have a model
of that name, it will be created for you automatically when you run the command.
The filepath to your fine-tuned model is in your Torchtune configuration file, under the output_dir key.
!huggingface-cli upload <your-username>/<your-model-name> <filepath-on-system-where-you-output-your-finetuned-model>
10. Verify your Fine-tuned Model
After fine-tuning, it's crucial to verify that our model is working as expected.
We can do this by loading the model and generating some text.
As an added bonus, our freshly published model will be downloaded from the Hugging Face Model Hub, in the same way that others will use it in the future, so this is also a good smoke test that publishing the model succeeded.
Be sure to replace the model_name and new_model parameters with the actual names you used when publishing your model.
You will probably want to update your prompt as well prior to testing.
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
from peft import PeftModel
model_name = "meta-llama/Meta-Llama-3.1-8B-Instruct"
new_model = "zackproser/Meta-Llama-3.1-8B-instruct-zp-writing-ft-qlora"
base_model = AutoModelForCausalLM.from_pretrained(model_name)
model = PeftModel.from_pretrained(base_model, new_model)
model = model.merge_and_unload()
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
pipe = pipeline(task="text-generation", model=model, tokenizer=tokenizer, max_length=2000, device=0)
prompt = "Write me an article about getting faster as a developer"
result = pipe(f"<s>[INST] {prompt} [/INST]")
print(result)
This code loads our fine-tuned model, creates a text generation pipeline, and generates an article based on a prompt.

Discussion
Giscus