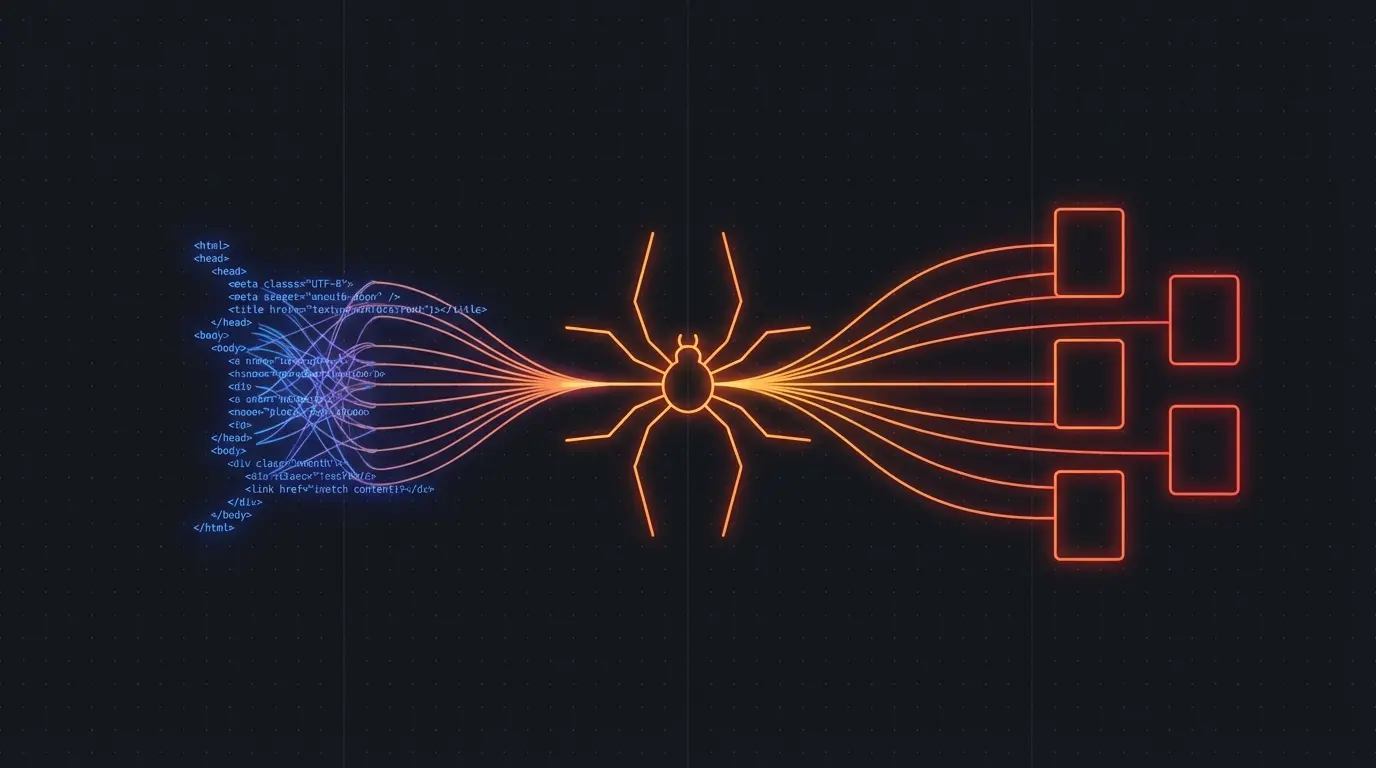

AI agents need access to information. Not just their training data — live, current information from the web. Product pages, documentation, news articles, forum discussions, pricing tables.
The problem: websites serve HTML meant for browsers, not structured data meant for LLMs. Your agent needs a way to turn any URL into clean, structured data it can reason over.
The Agent Research Loop
A typical web research agent follows this pattern:
- Query — determine what information is needed
- Search — find relevant URLs (via search API)
- Scrape — extract clean content from each URL
- Analyze — LLM processes the extracted content
- Synthesize — combine findings into a coherent answer
Steps 1, 2, 4, and 5 are LLM calls. Step 3 is the bottleneck — and it's where most agent implementations fall apart.
If your agent fetches raw HTML and passes it to the LLM, you're wasting context window on <div> tags, CSS classes, and navigation elements. Worse, the LLM might hallucinate information that was in the HTML noise rather than the actual content.
Giving Agents Clean Web Access
Firecrawl gives your agents a clean interface to the web. Instead of parsing HTML, your agent gets structured data:
import firecrawl
app = firecrawl.FirecrawlApp(api_key="fc-...")
def research_topic(urls: list[str]) -> list[dict]:
"""Agent tool: extract clean content from web pages."""
results = []
for url in urls:
page = app.scrape_url(url)
results.append({
"url": url,
"title": page.get("metadata", {}).get("title"),
"content": page.get("markdown"),
})
return results
Register this as a tool in your agent framework (LangChain, CrewAI, AutoGen, or vanilla function calling), and your agent can research any topic by scraping relevant pages and analyzing the clean markdown output.
Try Firecrawl FreeReal-World Agent Patterns
Competitive intelligence agent: Given a competitor's URL, crawl their site, extract pricing, features, and messaging. Compare against your own product. Output a structured battlecard.
I did exactly this in my Claude Cowork workshop — an AI agent crawled competitor sites, found user complaints on forums, and built battlecards automatically.
Documentation research agent: Before answering a technical question, the agent crawls the relevant documentation site to get current information rather than relying on potentially outdated training data.
Market research agent: Crawl industry blogs, news sites, and analyst reports to compile a market overview. The agent can run this weekly to track market changes.
Lead enrichment agent: Given a list of company names, crawl their websites to extract industry, company size, key products, and contact information.
Why Not Just Give Agents a Browser?
Some agent frameworks include browser automation (Puppeteer, Playwright). This works but introduces massive complexity:
- Slow. Launching and controlling a browser is orders of magnitude slower than an API call.
- Fragile. Browser automation breaks when sites change. Pop-ups, cookie banners, and CAPTCHAs add failure modes.
- Expensive. Each browser instance consumes significant memory and CPU.
- Overkill. For read-only research, you don't need to click buttons or fill forms. You just need the content.
Firecrawl gives agents what they actually need: clean content from any URL, fast, without managing browser infrastructure.
Try Firecrawl FreeTips for Agent Web Research
Cache aggressively. If your agent researches the same URLs frequently, cache the results. Web content doesn't change every minute.
Limit context. Don't feed your agent the full markdown from 20 pages. Summarize or extract relevant sections first.
Validate sources. Your agent should prefer established, authoritative URLs over random results. Include source URLs in the final output so humans can verify.
Handle failures. Some pages will fail to scrape (paywalls, heavy bot detection). Your agent should handle these gracefully and try alternative sources.
Related:

Discussion
Giscus