I write to learn, and publish to share.
Technical tutorials, field notes on applied AI, and developer writing from a long stretch shipping production systems. Updated most weeks.

 TDD-006 · DRAWING
TDD-006 · DRAWINGThe Model Sheet
The complete guide to choosing an LLM as a consumer: read the name field by field — parameters, dense versus MoE, training stage, distillation, abliteration and merges, quantization (GGUF, k-quants, imatrix, GPTQ/AWQ) — do the memory math that decides what runs locally, source and vet a model on Hugging Face, then test it on your own task instead of trusting a benchmark.

 TDD-015 · DRAWING
TDD-015 · DRAWINGctx: The Personal Context Engine Every One of My Agents Shares
Every agent I use — terminal, browser, phone, across Anthropic and OpenAI — started every conversation knowing nothing about me. So I built one shared memory they all plug into: a technical blueprint for a provider-agnostic personal context engine — one Postgres table, a hybrid retriever with an LLM reranker, and a scope wall enforced by the database, not by prompts.

 TDD-010 · DRAWING
TDD-010 · DRAWINGThe Attention Head
How induction heads copy patterns in transformers, and how attention maps, logit attribution, and causal ablation support different strengths of claim.

 TDD-014 · DRAWING
TDD-014 · DRAWINGThe Benchmark
Trace an AI benchmark score from sampled tasks through prompts, scorers, aggregation, uncertainty, contamination, and the decision it can support.

 TDD-013 · DRAWING
TDD-013 · DRAWINGThe Diffusion Model
A coordinate-consistent visual guide to diffusion and flow: forward noise, learned denoising, guidance, latent compression, DiT, sampling, and flow matching.

 TDD-012 · DRAWING
TDD-012 · DRAWINGThe Guard
A trust-boundary threat model for prompt injection in tool-using agents, with capability scoping, external authorization, and testable security metrics.

 TDD-011 · DRAWING
TDD-011 · DRAWINGThe Inference Engine
A worked guide to LLM inference memory, KV-cache paging, continuous batching, prefill, decode, quantization, and latency-capacity planning.

 TDD-004 · DRAWING
TDD-004 · DRAWINGThe Tokenizer
How tokenization works: BPE tokenizer training, ordered merges, byte fallback, token IDs, costs, multilingual tradeoffs, and why LLMs use tokens.

 TDD-005 · DRAWING
TDD-005 · DRAWINGThe Workshop
A complete working drawing for an AI training workshop: how to design, build, deliver, and follow through on an AI workshop for engineers or corporate AI training that works.
 10 · Essay
10 · EssayWe don't want AI pets. Fix your fucking connectors.
Hate mail from the edge of applied AI.

 TDD-002 · DRAWING
TDD-002 · DRAWINGThe Embedding Space
From the distributional hypothesis and word2vec to contextual sentence encoders: how embeddings are trained, compared, indexed with HNSW, migrated, and evaluated in production.

 TDD-003 · DRAWING
TDD-003 · DRAWINGThe RAG Pipeline
From open-domain question answering to production RAG: ingestion, chunking, BM25 and dense retrieval, reranking, context assembly, citations, evaluation, and failure tracing.
The Transformer
How seq2seq attention became the transformer, how decoder-only models generate, and how tokens, attention heads, position, residual blocks, sampling, KV caching, and scaling fit together.
 14 · Essay
14 · EssayWhy Granola Is My First Connector for Agentic Systems
How I route Granola meeting notes and transcripts into AI agents that draft posts, extract action items, create tickets, and write follow-ups.
15 · EssayOne Button Ended My Meeting Anxiety
How I use Granola to reduce meeting anxiety, check what I missed in real time, keep track of decisions, and stay present in every call.
 16 · Essay
16 · EssayThe Hero Glow-Up: My Whole Blog, Burning in Semantic Space
I replaced my portrait-centered homepage hero with the Mind on Fire mark rendered as living pixels, surrounded by every essay I've published as clickable constellations. Here's why, how it works, and the ember easter egg.
 17 · Essay
17 · EssayVercel's eve agentic framework review. Is eve worth it?
My verdict on eve, Vercel's open-source agentic framework: an emphatic yes. Why I reached for it after building the WorkOS blog bot, the separation-of-concerns lesson that made it the right call, what it nails, and the sharp edges to budget for.
 18 · Essay
18 · EssayWhat Makes an AI Workshop the Gold Standard
swyx told us our workshops are the gold standard for AI Engineer content. Here are the five principles behind that: ship the workshop as a product, make the room do the work, show people their own data, and build everything to keep running after the hour ends.
 19 · Essay
19 · EssayLifestyles of the AI-Native: Our Workshop at the AI Engineer World's Fair
Nick Nisi and I taught a hands-on hour at the AI Engineer World's Fair 2026: voice coding, agentic loops, verification gates, and scheduled tasks — one repo, four moves, and a live board showing the room reclaim hours of weekly toil in real time.
 20 · Essay
20 · EssayThe Agent Fleet That Runs My Business
How I run a solo AI consulting business from Slack: a fleet of single-purpose agents with the Claude tag as the meta-agent above them — reaching every surface, opening PRs, and maintaining the other bots — all behind a human approval gate.
 21 · Essay
21 · EssayYour Attention Is the Bottleneck, Not Your Agents
Agent capacity is cheap now and getting cheaper; my attention is the fixed, scarce resource. Everything I build is attention-budget design: the autonomy boundary, the PR gate, and running everything from Slack are all ways of spending my looking only where it counts. The written version of my AI Engineering London talk.
 22 · Essay
22 · EssayStop Building Chatbots. Build Agents That Open PRs.
The unit of useful agent work is a reviewable artifact — a PR, a draft, a diff — not a chat reply. A chat reply evaporates. A PR sits in a queue with your name on it until you decide. Here's why I build agents that hand me coals, using my own blog bot as the worked example.
 23 · Essay
23 · EssayI Make Codex Review Every Diff Claude Writes
Claude Code writes the diff. Before I see it, a Codex (GPT) reviewer reads the same diff with an adversarial brief and tries to break it. Cross-model review catches what self-review misses: the hook flow, the rubric, and the bugs it actually finds.
 24 · Essay
24 · EssayHow My Blog Bot Reviews Its Own Writing Before I Read It
Before a draft reaches me, my blog bot hands it to two cold readers from different model families that score it against a rubric and force a revision loop. The implementation, the gate, and a real pass where it caught my own AI tell.
 25 · Essay
25 · EssayThe Portfolio That Pays Rent
My personal site runs like a small business with three AI employees — content, ops, distribution — and me as editor-in-chief. Here's the org chart, the real ledger of what it earns and costs, and the work I still do by hand.
 26 · Essay
26 · EssayReviewing Vercel's eve agent framework by hiring my website three AI employees
I reviewed Vercel's eve agent framework by building a real three-agent business team for my site — content, ops, and growth bots that deploy to Vercel and collaborate over Slack and eve channels. The friction is part of the review.
 27 · Essay
27 · EssayHow to Wire an Anti-Slop Pass Into Your Blogging or Artifact Pipeline
If you generate anything with a model in the loop, you need a step that reads the finished draft against a list of AI tells and rewrites every hit. Here's how I wired one into my pipeline, where it sits, and the catch nobody mentions.
 28 · Essay
28 · EssayThe Autonomy Boundary
My rule for AI agents: anything reversible runs unattended, anything irreversible or outbound stops for a human. Here is how I drew that one line across three bots and enforced it in code, not willpower.
 29 · Essay
29 · EssayEverything I've Learned About Public Speaking
I went from blacking out on stage in front of 4,000 engineers to sleeping fine before jet-lagged days of talks abroad. Here's the whole pile of crumbs that got me there — medication, mindset, slides, reps, and putting your talks online.
 30 · Essay
30 · EssayI Am the Spark, the Bellows, and the Quench
A stranger online said AI made him suspicious of all writing — that he now interrogates every sentence asking whether a machine wrote it. That's the wrong question. On craft in the era of AI, and why I'm still the spark, the bellows, and the quench.
 31 · Essay
31 · EssayThe All-Apple House: A Paradise for Two Toddlers and an Aging Hacker
I wired my new place into an all-Apple smart home: Aqara cameras inside and out, a full eero mesh plus an outdoor repeater, Apple TVs, HomePod minis, smart plugs, and Siri automations. A paradise for two toddlers and an aging hacker. The hardware is solid. Siri is infuriating.
 32 · Essay
32 · EssayDevin AI Has Come a Long Way
A year ago at WorkOS nobody could get a single Devin AI session working. We abandoned it. Now Devin AI is one of our most-used agents in Slack — shipping PRs, fixing bugs, running data queries. And I'm using Devin AI to write blog posts with pixel art and three.js animations.
 33 · Essay
33 · EssayThe Interface Matters Most
You have about ten seconds to wow your user and convince them you're already solving their problem. The model, the stack, the architecture — none of it matters if the door is wrong. Time-to-value is the moat now.
 34 · Essay
34 · EssayWho Is an Illusion. What Is the More Interesting Question.
Applying systems thinking to my internal experience.
 35 · Essay
35 · EssayApplied AI: Three Learnings from Shipping — My Talk at the WorkOS Applied AI Showcase
I closed the WorkOS Applied AI Showcase with three learnings from shipping internal AI tooling: interface beats stack, complete the loop, and the imagination gap. Bartleby vs Blog Bot, capture → plan → execute → ship, and re-asking the question every quarter.
 36 · Essay
36 · EssayIntensity and I
We called him Intensity. He chain-smoked at the edge of every room. Twenty years later in a therapist’s chair my partner used the same word on me.
 37 · Essay
37 · EssayMy Algorithm
Gasoline and electricity, the line that won't dim. Forty years inside the appetite I have never been able to turn off.
 38 · Essay
38 · EssayGoing Guerilla on My Inbox
What my AI inbox-screener actually does to the templated cold outreach hitting my inbox. Three real auto-sends, the footer that draws the line, and where this goes next.
 39 · Essay
39 · EssayI Built an AI Email Inbox That Replies — With Safety Checks
A human-in-the-loop AI inbox classifier that drafts replies, with a per-category graduation ladder that lets each earn its way to auto-send.
 40 · Essay
40 · EssayWhy my site has a rate card now
I shipped a partnerships page. This is the why-now: capacity, an inbox auto-classifier I haven't built yet, and the years of compounding work that made it the right moment to tie it together.
 41 · Essay
41 · EssayHow to Play Steam Link on Vision Pro While Watching TV
After weeks of frustration, I cracked zero-lag Steam Link streaming to Apple Vision Pro. Here's the exact setup that works — and all the wrong turns I took getting there.
 42 · Essay
42 · EssayMy AI Agent Has a Mechanic Agent
Hermes was producing shallow responses. Instead of debugging from the inside, I opened Claude Code, SSH'd into the EC2 instance, found the throttled context window, fixed it, and restarted the gateway. Hermes woke up improved — without knowing it happened.
 43 · Essay
43 · EssayWhat It Feels Like To Be a Neurodivergent Engineer (Interactive)
An interactive primer on the ADHD engineering brain — a 3D brain you can put through hyperfocus and crash, a simulator for what reading feels like under intrusive thoughts and notification overload, and the AI scaffolding I use to work around all of it.
 44 · Essay
44 · EssayI Shipped 9 Blog Posts in 48 Hours While Working Full-Time
Between a full-time job at WorkOS and solo-parenting two toddlers with zero screen time, I published 14,790 words across 9 posts in two days. 47 images, 12 PRs. The secret: chatops with two AI agents I drive in compressed windows.
 45 · Essay
45 · EssayA Conference Workshop Playbook: What We Learned Teaching 200+ Engineers
Practical lessons from running hands-on technical workshops at AI Engineer World Fair SF, AI Engineering London, and beyond. What works, what doesn't, and why most conference workshops suck.
 46 · Essay
46 · EssayHow My AI Assistant Ships Blog Posts
My AI assistant Hermes writes MDX content, generates hero images, uploads to Bunny CDN, commits to git, opens pull requests, and merges — all from a Discord conversation.
 47 · Essay
47 · EssayNick Nisi Is One Talented Motherfucker
An appreciation post for my colleague and friend Nick Nisi — TypeScript wizard, conference organizer, and the best workshop partner I could ask for.
 48 · Essay
48 · EssayOne Phone, Two Agents
I run two AI agents — Claude Code for infrastructure, Hermes for content — both controlled from my phone. Here's the split-brain architecture and why separation of concerns matters for AI agents too.
 49 · Essay
49 · EssayThe Webhook Bridge Pattern: How Claude Code Talks to a Remote AI Agent
Solving the 'silent files' problem: how I built an event-driven bridge between Claude Code on my Mac and the Hermes agent running on EC2, using SSM RunCommand, Tailscale, and HMAC-signed webhooks.
I Built an Always-On Hermes Agent on AWS in a Day, Mostly Async
How I moved my personal AI assistant to AWS with OpenTofu, Tailscale, and Discord — self-hosting Hermes Agent in the margins of a normal workday.
 51 · Essay
51 · EssayLive on the Scaling Devtools Podcast at AI Engineering London
I sat down with Jack Bridger on the Scaling Devtools podcast at AI Engineering London to talk about how WorkOS builds with AI coding agents, the patterns behind portable skills, and where developer tooling is heading.
 52 · Essay
52 · EssaySkills at Scale: Our Workshop at AI Engineering London
Nick Nisi and I ran an 80-minute hands-on workshop at AI Engineering London on building Claude Code skills that are portable, executable, and composable. We taught constraints over instructions, evidence over guesses, and measurement over vibes.
 53 · Essay
53 · EssayUntethered Productivity: My Talk at AI Engineering London
I gave a talk at AI Engineering London about staying healthy, creative, and shipping while working with AI coding agents. The core idea: the agents scale infinitely, but your nervous system doesn't. Here's the full recap.
 54 · Essay
54 · EssayClaude Code on Your Phone: How Remote Control Connects Your Terminal to iOS and Android
Claude Code's Remote Control feature lets you continue local terminal sessions from your phone. Here's how it works, what it can and can't do, and how it compares to Claude Code on the web.
 55 · Essay
55 · EssayThe List of People and Things That Have Failed to Kill Me
A running tally.
 56 · Essay
56 · EssayThe LLM Is Not My Friend (It's Something More Useful)
I talk to my AI assistant like a person. I give it access to everything. And no, I don't think it's sentient. Here's why that's the point.
 57 · Essay
57 · EssayOpenAI Codex Review 2026 — Updated from Daily Use
After nearly a year of daily Codex use across personal and WorkOS projects, here's what has actually changed and improved
 58 · Essay
58 · EssayMy 2026 AI Engineer Setup
Claude Code replaced Cursor. Granola replaced meeting notes. WisprFlow still runs everything. The setup got quieter and the output went up.
 59 · Essay
59 · EssayHandwave: Talk to Your Claude Code Sessions From Your Watch
I built a watchOS app that lets me speak to any of my Claude Code sessions from my wrist. When you can't sit still, bring your AI with you.
 60 · Essay
60 · EssayExperiment: Using Native macOS Apps to Install AI Workflows for Teammates
Why I built a native Swift installer instead of writing another setup guide
 61 · Essay
61 · EssayThe Orchestrator Pattern: Orchestrating AI Agents Like a Mission Control Engineer
A single developer can now direct multiple agentic coding agents across maintenance tasks while simultaneously building features in Cursor. Here's how the Orchestrator Pattern changes software development.
 62 · Essay
62 · EssayTraining Claude to Compensate for My Neurological Patterns
How I'm systematically teaching an AI system to compensate for specific ADHD/autism processing patterns—building collaborative intelligence that works with my neurology.
 63 · Essay
63 · EssayWalking and Talking in the Woods with AI: The Future of Untethered Software Development
A DevSecCon 2025 keynote summary: orchestrate voice, agents, and a hardened CI/CD lane so you can think where you think best—while background agents safely ship production-grade code.
 64 · Essay
64 · EssayWisprFlow Review: I Write Code at 179 WPM
I dictate code, docs, and Slack messages at 179 words per minute. WisprFlow is the first voice tool that actually works for developers.
 65 · Essay
65 · EssayHow to Connect Your Oura Ring to Claude Desktop with MCP
Turn your health data into actionable insights with AI-powered analysis. Learn how to integrate your Oura Ring with Claude Desktop using the Model Context Protocol.
 66 · Essay
66 · EssayIn the LLM, I Saw Myself
How LLMs mirrored my neurodivergent thinking, helped me connect the dots, and became the glue in a personal cognitive toolkit.
 67 · Essay
67 · EssayBeat Coding Interview Anxiety with ChatGPT and Google AI Studio
How ChatGPT and Google AI Studio helped me reduce live coding anxiety through systematic practice
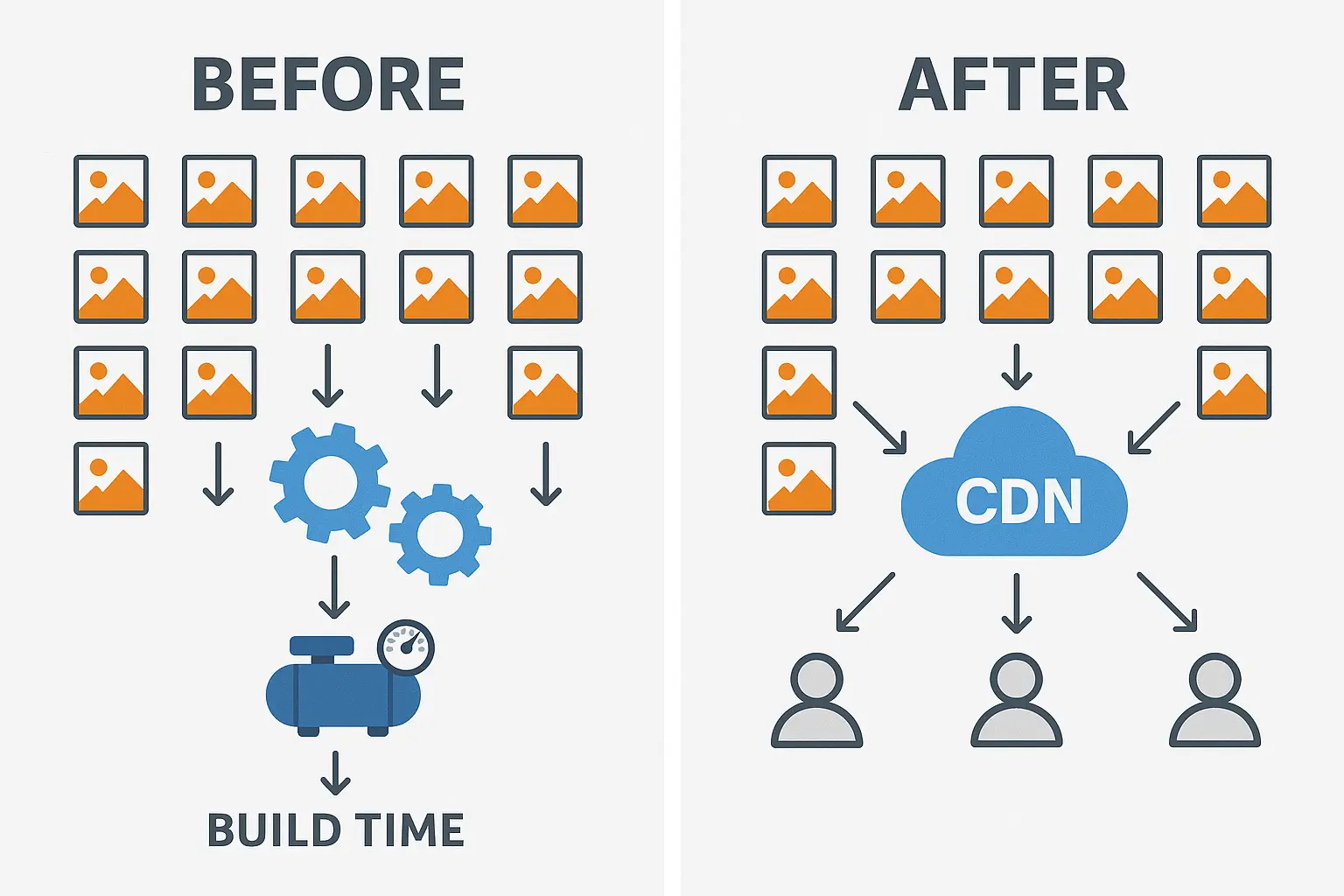 68 · Essay
68 · EssayHow I Cut My Vercel Build Time by 66% (5.5 Minutes to 1 Min 53 Seconds)
A detailed breakdown of how I optimized my Next.js site's build process, moving from static generation to ISR, migrating images to CDN, and implementing on-demand OpenGraph image generation.
 69 · Essay
69 · EssayCorporate AI Catch-22
The corporate AI catch-22: move fast and break things, or move slow and get disrupted. Lessons from real-world AI enablement.
 70 · Essay
70 · EssayLive Workshop: AI Pipelines & Agents in TypeScript w Mastra.ai - Nick Nisi and Zack Proser
Nick Nisi and I taught 70 engineers how to build AI workflows and agents with Mastra.ai at the AI Engineer World Fair in San Francisco.
 71 · Essay
71 · EssayGoogle Jules Hands-on Review
On May 20th, 2025, I gained access to Google Jules research preview. Here is what I think
 72 · Essay
72 · EssayLLMs democratize specialist outputs. Not specialist understanding
It is easier than ever to learn development, but the folks getting the most leverage are still seasoned engineers. Why?
 73 · Essay
73 · EssayVibe Coding Mastery
How to code safely and efficiently with Git, secrets, and Cursor setup.
 74 · Essay
74 · EssayVibe Coding Survival Guide – Secrets & Git Basics for Cursor-First Builders
A no-jargon crash-course that keeps your AI side-projects from torching your wallet. Perfect for vibe coders with zero engineering background.
 75 · Essay
75 · EssayThe Vercel AI SDK: A worthwhile investment in bleeding edge GenAI
The Vercel AI SDK takes some time to get used it. It is time well spent.
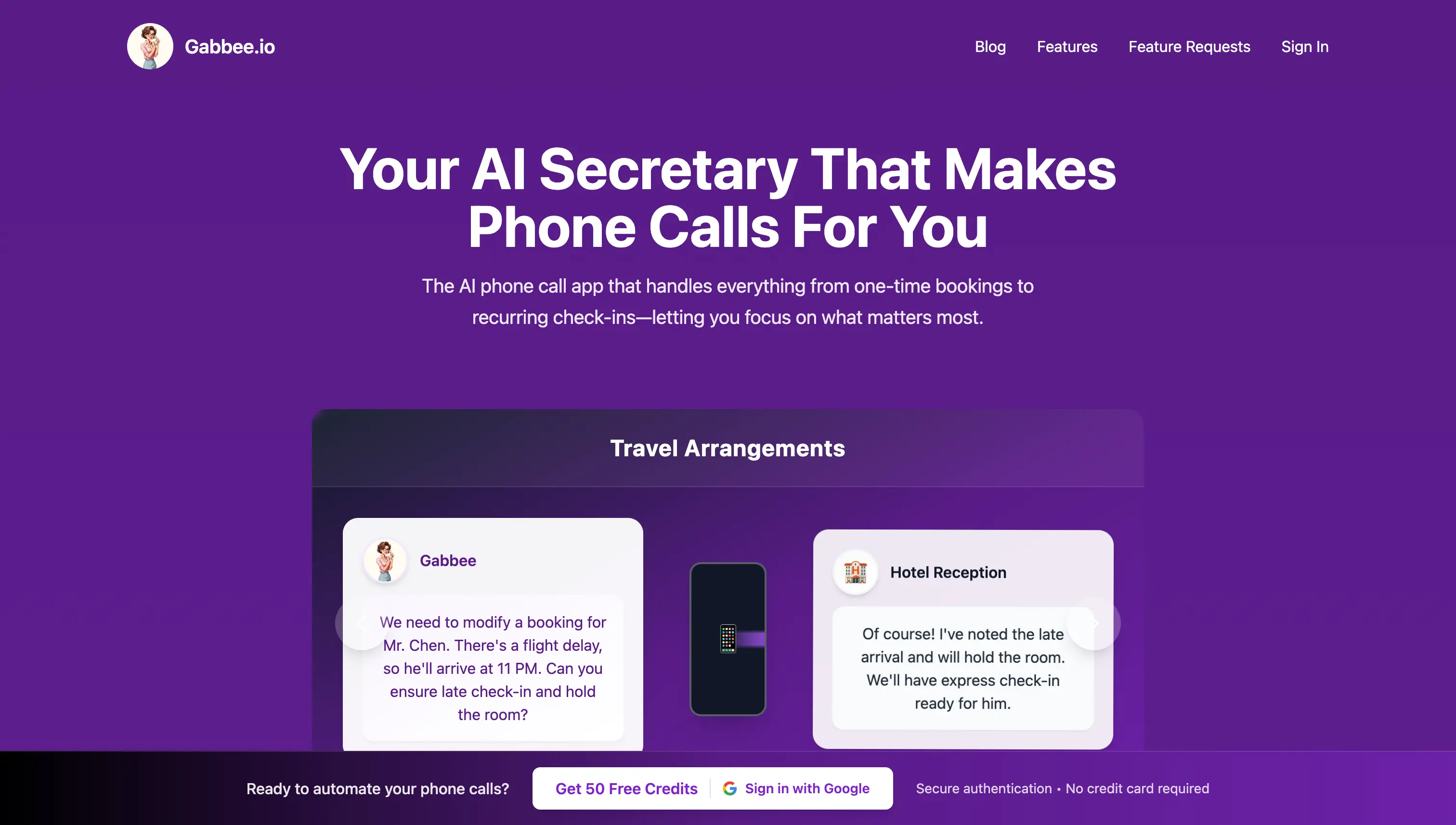 76 · Essay
76 · EssayIntroducing Gabbee.io: AI BDR for Zoho CRM
Meet Gabbee.io, an AI BDR that programmatically validates leads via human-sounding phone calls. Automatically qualifies prospects using BANT methodology and syncs directly with Zoho CRM.
 77 · Essay
77 · EssayTutorial: Build a RAG pipeline with LangChain, OpenAI and Pinecone
Step by step tutorial: how to build a production-ready RAG pipeline.
 78 · Essay
78 · EssayHow to automatically switch git profiles based on the current directory
You can automate your git profile switching based on the current directory. Here's how to do it.
 79 · Essay
79 · EssayHow I grew my tech blog to 35,000 readers in a year
Learn how I grew my tech blog to 35,000 readers in one year through site optimization, UX improvements, consistent publishing, and building useful tools.
 80 · Essay
80 · EssayCloud GPU Services for Deep Learning and fine-tuning with Jupyter Notebooks Reviewed: Colab, Paperspace Gradient, Lightning.ai, and more
I tried a handful of services when I last needed to fine-tune an LLM, and I was mostly disappointed...
 81 · Essay
81 · EssayHow to create a custom Alpaca instruction dataset for fine-tuning LLMs
A step by step tutorial with companion notebook.
 82 · Essay
82 · EssayHow to Fine-tune Llama 3.1 on Lightning.ai with Torchtune
One of the better Jupyter Notebooks to GPU-backed environment experiences I've had...
 83 · Essay
83 · EssayMLOps Adventure - Learning to Fine-tune LLMs, create datasets and neural nets
I've been on an MLOps adventure lately, taking any excuse to get hands on with neural nets, fine-tuning, Hugging Face datasets and models.
 84 · Essay
84 · EssayThe Rich Don't Fine-tune Like You and Me: Intro to LoRA and QLoRA
LoRA and QLoRA are two important innovations related to fine-tuning large language models like Llama and GPT.
 85 · Essay
85 · EssayAutocomplete is not all you need: Why Cursor and Zed are going to dominate
AI assisted developer tooling is not created equally...
 86 · Essay
86 · EssayCursor review: Changing the way I create software
I have been experimenting with AI assisted dev tools nonstop. Cursor probably had the biggest impact of all, so far.
 87 · Essay
87 · EssayThe Giant List of AI-Assisted Developer Tools Compared and Reviewed
A comprehensive comparison and review of AI-assisted developer tools, including code autocompletion, intelligent terminals/shells, and video editing tools.
 88 · Essay
88 · EssayBuilding a Hand-Drawn Digit Recognizer with PyTorch and MNIST
I trained a neural net to recognize hand-drawn digits, then built a Next.js UI for it
 89 · Essay
89 · EssayWhy I bought three System76 computers
In the past 4 years, I have bought and used 3 different system76 linux machines. Here's why.
 90 · Essay
90 · EssayHow are embeddings models trained for RAG?
Embeddings models are the secret sauce that makes RAG work. How are THEY made?
 91 · Essay
91 · EssayMy morning routine
For several years now I've been getting up early before work to get plenty of me time in...
 92 · Essay
92 · EssayBuild a RAG pipeline for your blog with LangChain, OpenAI and Pinecone
You can chat with my writing and ask me questions I've already answered even when I'm not around
 93 · Essay
93 · EssayVector Databases in Production for Busy Engineers: RAG Evaluation
I wrote the RAG evaluation chapter for Pinecone's latest book
 94 · Essay
94 · EssayVector Databases in Production for Busy Engineers: CI/CD
I wrote the CI/CD chapter for Pinecone's latest book
 95 · Essay
95 · EssayTech I wish existed: super hearing aids
I want comfortable hearing aids with long battery life that extend my senses and intelligence
 96 · Essay
96 · EssayWhy I use Neovim's AstroNvim project as my daily driver IDE
Why do I use an open-source IDE-like Neovim experience glued together with Lua?
 97 · Essay
97 · EssayUpdated Codeium analysis and review
It's been about a year since I last looked at Codeium - what has changed?
 98 · Essay
98 · EssayHow do you write so fast?
Sometimes someone will ask me how I am able to write new content so quickly. This is my answer.
 99 · Essay
99 · EssayThe best programmer ever
A brief story about the best programmer I ever worked with
 100 · Essay
100 · EssayBuilding data-driven pages with Next.js
To effectively maintain richer and more complex web experiences, separate data from presentation.
 101 · Essay
101 · EssayWarp AI terminal review
The Warp terminal is a serious boon for anyone looking for help on the command line, but it's not yet perfect
 102 · Essay
102 · EssayThe best thing about being a developer
The best thing about being a developer is being able to build your own tools, to your exact specifications.
 103 · Essay
103 · EssayHop on the pain train
Some junior engineers are so afraid of breaking something, they paradoxically stagnage themselves
 104 · Essay
104 · EssayPinecone vs Chroma
A detailed comparison of the Pinecone and Chroma vector databases
105 · EssayPinecone vs FAISS
A detailed comparison of the Pinecone and FAISS vector databases
106 · EssayPinecone vs Milvus
A detailed comparison of the Pinecone and Milvus vector databases
107 · EssayPinecone vs Weaviate
A detailed comparison of the Pinecone and Weaviate vector databases
 108 · Essay
108 · EssayTrace the system in your head
One of the best engineering managers I ever had was at Cloudflare. Here's what he did in his free time...
109 · EssayWeaviate vs Chroma
A detailed comparison of the Weaviate and Chroma vector databases
110 · EssayWeaviate vs FAISS
A detailed comparison of the Weaviate and FAISS vector databases
111 · EssayWeaviate vs Milvus
A detailed comparison of the Weaviate and Milvus vector databases
 112 · Essay
112 · Essayaws-vault - the best way to manage AWS credentials for multiple accounts
aws-vault is an excellent open-source tool written in Golang that allows you to manage the credentials for multiple AWS accounts securely.
 113 · Essay
113 · EssayHow to Run background jobs on Vercel without a queue
I recently needed to figure out how to have my Vercel API route accept a new job and return a response immediately while still performing long running processing in the background. This is what I learned.
 114 · Essay
114 · EssayGit operations in JavaScript for pain and profit
You can run git wherever JavaScript is accepted. Should you?
 115 · Essay
115 · EssayIntroduction to dimensionality in machine learning
Dimensionality refers to the number of features a given embedding model extracts
 116 · Essay
116 · EssayIntroduction to embeddings (vectors) and how they work
Embeddings are numerical representations of the key features of some data
 117 · Essay
117 · EssayVector Databases Compared: Pinecone, Milvus, Chroma, Weaviate, FAISS, and more
How do the different vector databases compare?
 118 · Essay
118 · EssayHow to build a dynamic sitemap for your Next.js project
Steal my implementation to save yourself some time and headaches
 119 · Essay
119 · EssayMy first book credit! My Horrible Career
What started out as an extended conversation with my mentor about career trajectory became a book!
 120 · Essay
120 · EssayCodeium vs ChatGPT
What's the difference between Codeium and ChatGPT and which should you use?
Testing Pinecone Serverless at Scale with the AWS Reference Architecture
A step-by-step walkthrough on how to generate arbitrary system load and flex Pinecone Serverless
 122 · Essay
122 · EssayKeep Calm and Ship Like Crazy: My 2023 Wins and Lessons
I had a lot of growth and success to celebrate professionally in 2023
 123 · Essay
123 · EssayA Blueprint for Modern API Development: Repositories developers want to work on
Developer delight === project velocity ?
 124 · Essay
124 · EssayEvolving web scraping: How Pageripper API handles JavaScript-heavy sites
Pageripper API uses Puppeteer and headless Chrome under the hood to see the same thing your browser does, even for Single Page Applications (SPAs)
 125 · Essay
125 · EssayPageripper API: a commercial data-extraction service
I built an API that extracts data from webpages, even if they're rendered with Javascript. It's defined via Pulumi and deployed on AWS.
 126 · Essay
126 · EssayTalk @ a16z: Taking AI applications to Production
I introduced the new Pinecone AWS Reference Architecture with Pulumi and explained infrastructure as code
 127 · Essay
127 · EssayComic: Magic spells
A comic strip about casting magic spells
 128 · Essay
128 · EssayComic strip: long day at the office
A wordless comic strip about a typically brutal day at work, that nevertheless has a positive ending
Announcing the Pinecone AWS Reference Architecture in Pulumi
Deploy production-ready systems using Pinecone in minutes with the AWS Reference Architecture
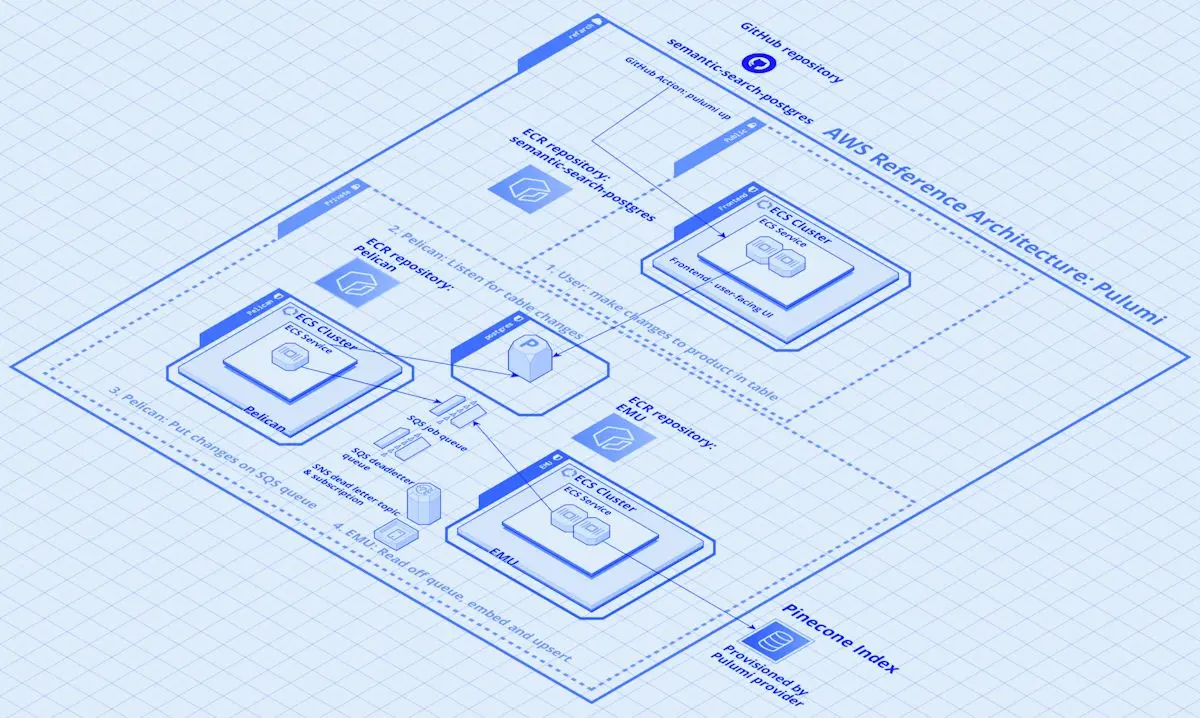 130 · Essay
130 · EssayPinecone AWS Reference Architecture Technical Walkthrough
An examination of the Reference Architecture components and functionality
 131 · Essay
131 · EssayWash three walls with one bucket
Design your side projects, blog posts and even your fun experiments to triangulate multiple learning paths simultaneously. Then, use them to build out your portfolio.
 132 · Essay
132 · EssayRun your own tech blog
Control your own destiny, build your personal brand, and master web technologies by running your own tech blog.
 133 · Essay
133 · EssayFor Zachary
There are only two people I am aware of named Zachary Proser, with that exact spelling. This article is only for Zachary Proser.
 134 · Essay
134 · EssayHow to generate images with AI
I have used StableDiffusion, AUTOMATIC111, DALLE and Discord bots to generate images in every style for blog posts. You can too.
 135 · Essay
135 · EssayYou get to keep the neural connections
Going the extra mile only to be unrewarded by your company feels like a personal slight and a waste of your time. It is not.
 136 · Essay
136 · EssayChatGPT4 and Codeium are still my favorite dev assistant stack
As of October 10th, 2023, ChatGPT4 and Codeium are still my favorite AI-assisted dev tool stack. Here is why
 137 · Essay
137 · EssayThe top bugs all AI developer tools are suffering from
I have evaluated everything from ChatGPT to CoPilot to Codeium to Cursor, to Sourcegraph Cody to CodiumAI. All suffer from the same bugs
 138 · Essay
138 · EssayGitHub Copilot review
I got Copilot access for free as an active GitHub open-source maintainer, but would I pay for it?
 139 · Essay
139 · EssayWhy your AI dev tool startup is failing with developers
These common mistakes are dooming your AI-assisted developer tooling startup to failure. Don't make them
 140 · Essay
140 · EssayHow I keep my shit together
Practices and protocols that keep me humming along, healthy and productive on a given day
 141 · Essay
141 · EssayMaking it easier to maintain open-source projects with CodiumAI and Pinecone
CodiumAI's PR-agent integration leverages Pinecone under the hood to perform semantic search for similar GitHub issues
 142 · Essay
142 · EssayProgrammer emotions
Programmers are people, and this is how I feel when...
 143 · Essay
143 · EssayGlossary of tech phrases
If you're coming from Hacker News, I've learned that I need to spell out at the beginning that this post is partly facetious...
 144 · Essay
144 · EssayThe Pain and Poetry of Python
A history of package management and virtualenvs in Python and why we migrated the Pinecone Python client to Poetry
 145 · Essay
145 · EssayHow to use Jupyter Notebooks to do Machine Learning and AI tasks
Jupyter Notebooks are surprisingly easy to get started with - especially when using GitHub and Google Colab
 146 · Essay
146 · EssayOpengraph dynamic social images
I built a custom opengraph image with '@vercel/og' that includes a fallback image for index pages
 147 · Essay
147 · EssayAI-powered and built with...JavaScript?
6 Technology trends position JavaScript developers to reap the rewards of the GenAI boom
 148 · Essay
148 · EssayRetrieval Augmented Generation (RAG)
How to reduce hallucinations in your Generative AI applications
 149 · Essay
149 · EssayI'm joining Pinecone.io as a Staff Developer Advocate!
Making the pivot from pure software engineering to developer advocacy
 150 · Essay
150 · Essayggshield can save you from yourself. Never accidentally commit secrets again
Stop yourself from committing a secret to git with ggshield
 151 · Essay
151 · EssayFirst, find out if you've got the programming bug
I get this question a lot: how do I get into coding? This is my best advice.
 152 · Essay
152 · EssayOffice Oracle - a complete AI Chatbot leveraging langchain, Pinecone.io and OpenAI
I open sourced my next.js AI chatbot and the Jupyter notebooks I used to build it, plus created a video series walking through it all on YouTube
 153 · Essay
153 · EssayCodeium with Neovim for A.I. powered code-completion: so far so good
Generally unimpressed with GitHub's Copilot (not Copilot X), I gave the alternative, Codeium a shot.
 154 · Essay
154 · EssayAutomations - shell scripts leveraging OpenAI to make your developer workflow buttery smooth and way more fun
I have open sourced my automations project, which is a collection of shell scripts that automatically handle git operations, provide local code reviews, pull requests, and more!
 155 · Essay
155 · EssayAutogit - never forget to pull the latest changes again
Autogit is an open source shell script that you can wire up to your `cd` command to ensure you always have the latest code, branches, and remotes when you open up a local git repository.
 156 · Essay
156 · EssayPasswordless sudo and verified GitHub commit signing with Yubikey - a pair-coder's dream
If you're like me, you can't type your complex password correctly when your entire team is staring at you on a pair call. And now, you no longer have to.
 157 · Essay
157 · EssayMaintaining this site no longer fucking sucks
After re-doing my personal website in next.js and deploying to Vercel, I reflect on how much better the developer experience has become.
 158 · Essay
158 · EssayThe Bubbletea (TUI) State Machine pattern
Combining a lightweight state machine plus the Bubbletea charm library leads to a very powerful pattern for tooling that needs to orchestrate slow or expensive steps.
 159 · Essay
159 · EssayMaintaining this site fucking sucks
Join me as I delve into the infuriating, yet enlightening journey of maintaining my own Javascript-heavy website. Learn how battling DNS issues, dependency chaos, niche CSS pre-processors and constant painful upgrades has led to one of the most rewarding projects I've ever created.
 160 · Essay
160 · EssayCan ChatGPT-4 and GitHub Copilot help me produce a more complete side project more quickly?
As a Senior Software Engineer, I'm always looking for ways to refine my skills and optimize my workflow. This weekend, I experimented with integrating ChatGPT-4 into my developer toolkit alongside GitHub Copilot, which I've been using for several months. The goal? To see if these AI-powered tools could help me complete a side project more quickly.
 161 · Essay
161 · EssayWhy I've been successful lately, and what I'm planning to do about it
In the past 3 years, I've been promoted 3 times. I reflect on the habits and activities that helped me improve the most.
 162 · Essay
162 · EssayHow to securely store secrets in BitWarden CLI and load them into your shell when needed
A tutorial on how to write and use shell functions to fetch your tokens from the BitWarden CLI with one command.
Teatutor Deep Dive
Teatutor is a Golang CLI leveraging the Bubbletea Terminal User Interface (TUI) library from Charm.sh. It can be served over an SSH connection.
 164 · Essay
164 · EssayA powerful and open source content optimizer
A full technical deep-dive on my optimizer app and its features
165 · EssayHow to work with CircleCI more effectively
Pro tips for working with CircleCI configurations
 166 · Essay
166 · EssayWriting code on Mac or Linux but testing on Windows with hot-reloading
As a developer, I often want to test my code on Windows, but don't have a Windows box handy. This tutorial demonstrates how to use Infrastructure as Code (IaC) to make provisioning Windows test instances easier. In this post, I also provide a working Packer template and Terraform configuration to deploy your own Windows test instance, as well as instructions for mounting a local folder over RDP.
 167 · Essay
167 · EssayTerminal velocity - how to get faster as a developer
I obssess a decent amount over my own developer productivity and my customized tmux, neovim and awesome window manager linux setup, and now I pass my best learnings on to you
 168 · Essay
168 · EssayHow to Run a Quake 3 Arena Server in an AWS ECS Fargate Task
A tutorial, along with working Terraform code and Dockerfile, that you can use to deploy and operate your own Quake 3 server in an ECS task.
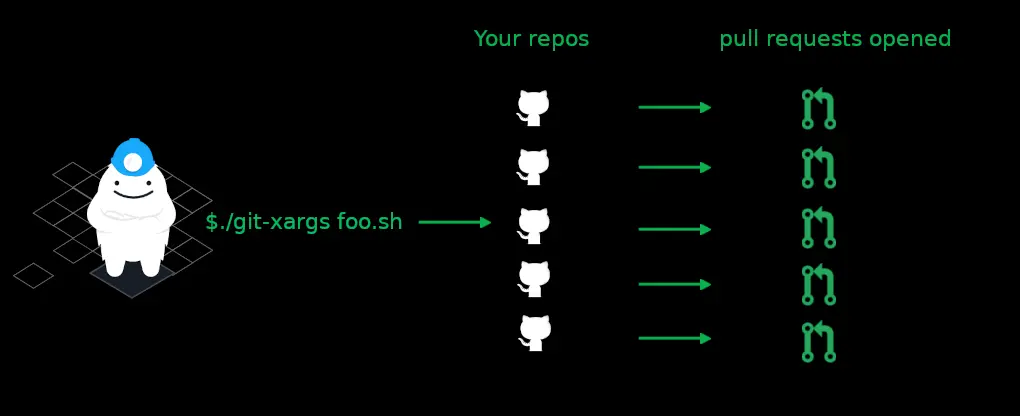 169 · Essay
169 · EssayGit-xargs allows you to run commands and scripts against many Github repos simultaneously
Git-xargs allows you to run commands and scripts against many Github repos simultaneously
How to build a React.js and Lambda app with Git push continuous deployment
An open-source example repository and technical deep-dive on using AWS SAM, Golang, CodePipeline and CloudFormation to automate continuous delivery.
 171 · Essay
171 · EssayCatFacts rewrite in Golang
A ridiculously over-engineered CatFacts prank written in Golang and deployed via Kubernetes
 172 · Essay
172 · EssayCanyonRunner - a complete HTML5 game
I open sourced my first HTML5 game as a resource for other developers working with Phaser.js or wanting to build their own game
173 · EssayCatFacts in Node.js
PICK UP THE PHONE - ITS CATFACTS!
174 · EssayBuilding the ultimate portfolio site with Nuxt.js and Netlify.
A technical deep dive on building a portfolio site that is beautiful, blazing fast and 100% SEO optimized
 175 · Essay
175 · EssayWisdomseeker
A wikipedia crawling application